RAG is not a model problem, it is an architecture problem
Why the success of RAG depends on system design, data orchestration, and retrieval strategy rather than just the LLM.
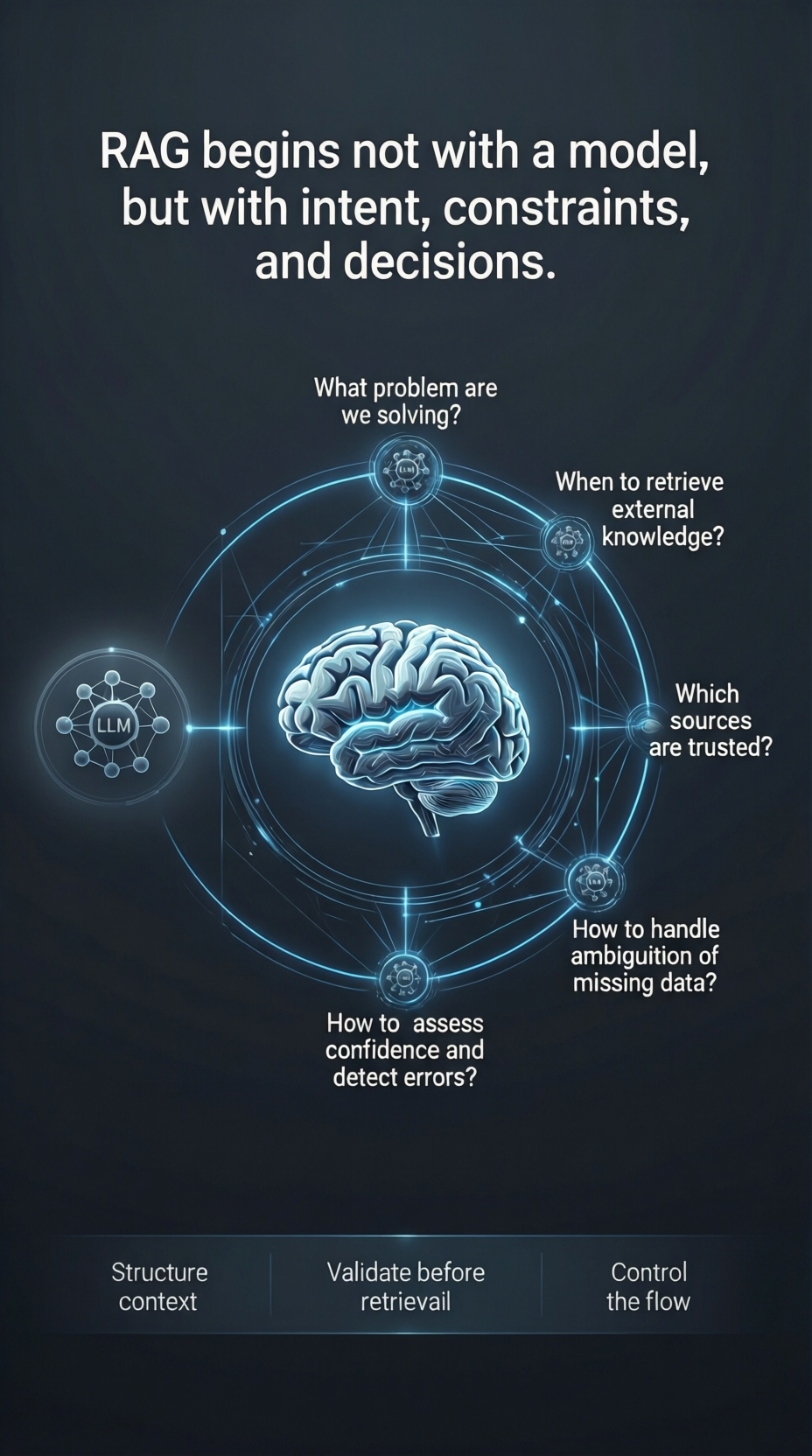
RAG is not a model problem, it is an architecture problem
When a RAG system fails, the first instinct is often to blame the LLM. “The model is hallucinating.” “The model isn’t smart enough.” In reality, the model is usually just reacting to what it was given. RAG is not a model problem. It is an architecture problem.
The LLM is only the final stage of a complex pipeline. Long before the model generates a single word, several critical architectural decisions have already determined the quality of the outcome:
• Data Quality & Governance: If the source data is noisy, outdated, or poorly structured, no model can fix it. • Chunking Strategy: How knowledge is fragmented determines whether context is preserved or destroyed. • Embedding Choice: The mathematical representation of your data defines what the system can “see” and relate. • Retrieval Logic: Finding the “right” chunks requires more than just vector similarity; it requires re-ranking, filtering, and metadata awareness. • Context Orchestration: How retrieved information is presented to the model—and how conflicts are handled—is where reasoning happens.
If any of these stages are weak, the system fails. And it fails in ways that the LLM cannot compensate for.
Building a RAG system is not about “plugging in a model.” It is about designing a system that manages the flow of context. In production, success depends on how well you architect the relationship between your data and the model’s reasoning capabilities.
The model provides the intelligence, but the architecture provides the truth. If the truth is missing, fragmented, or poorly retrieved, intelligence alone is not enough.
#RAG #AI #AIArchitecture #AIEngineering #EnterpriseAI #SystemsThinking