Chunking is where most RAG systems are already losing context
Beyond models and databases, chunking is the architectural decision where context is either preserved or destroyed in RAG systems.
Chunking is where most RAG systems are already losing context
Most RAG discussions focus on models or vector databases, but many systems fail long before retrieval happens. They fail at chunking.
Chunking is often treated as a simple preprocessing step: split every N tokens, add overlap, and move on. This approach quietly destroys context. When documents are fragmented without understanding structure and intent, meaning is lost.
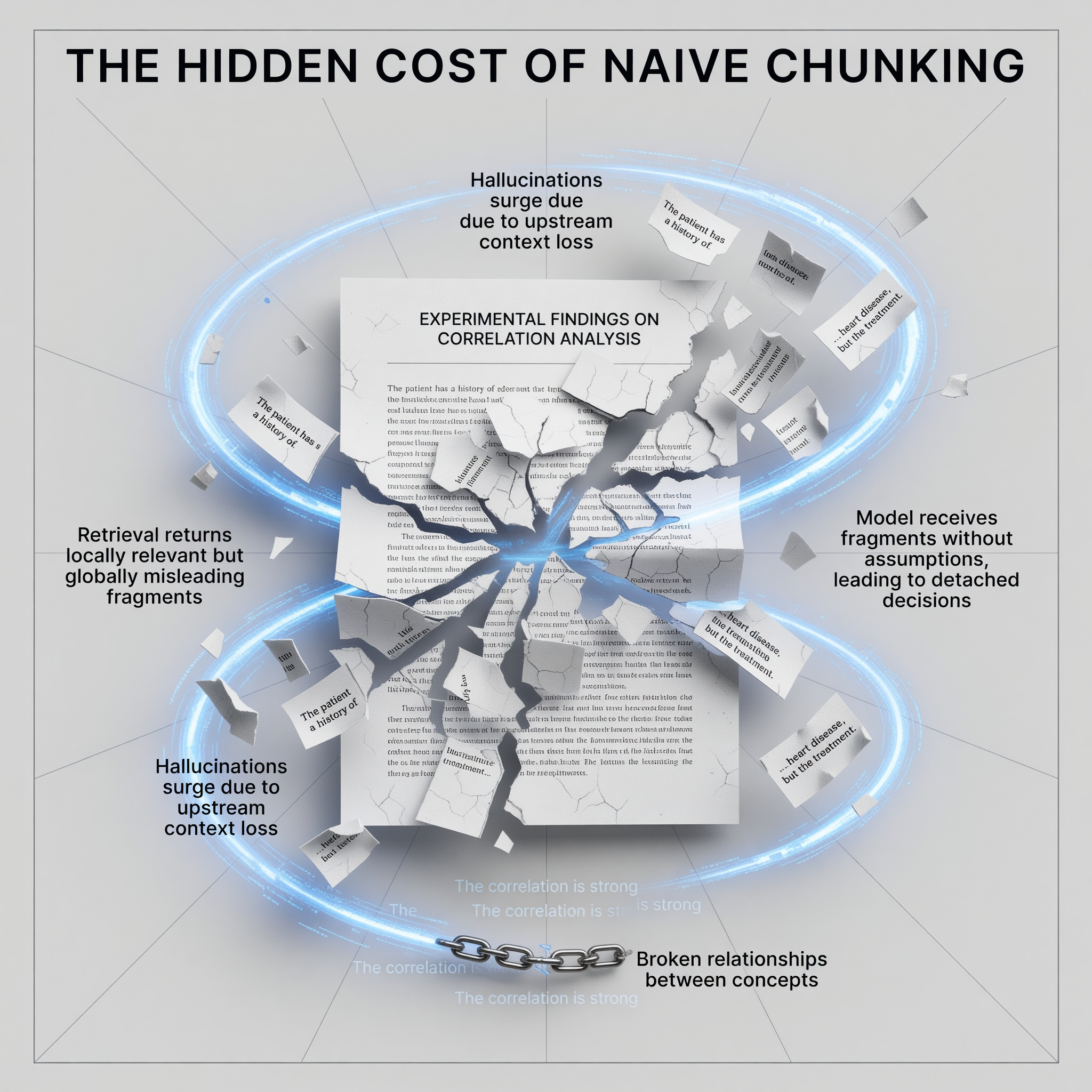
The Impact of Poor Chunking:
- Broken Relationships: Concepts and assumptions are separated from their conclusions.
- Misleading Retrieval: Returns text that is locally relevant but globally misleading.
- Increased Hallucinations: The model misses critical constraints because context was lost upstream.
Chunking is a representation problem, not a sizing problem. Humans think in sections and dependencies, not fixed token windows.
In production RAG systems:
- Chunks should preserve semantic completeness.
- Boundaries should align with meaning, not formatting.
- Context should be retrievable as a coherent unit.
This is why two RAG systems with the same documents, the same embeddings, and the same LLM can behave very differently. One feels grounded and precise. The other feels shallow and error-prone.
The difference is not retrieval. It is what was lost before retrieval ever began.
If a RAG system struggles with relevance, accuracy, or consistency, the problem is often not the model. It is how knowledge was broken apart.
Chunking is where context is either preserved or destroyed. And most systems make that decision without realizing its impact.
#RAG #AIArchitecture #Chunking #Embeddings #AIEngineering #EnterpriseAI #SystemsThinking